I am a research scientist in the National Key Laboratory of General Artificial Intelligence at Beijing Institute for General Artificial Intelligence (BIGAI), working on building intelligent robot system that can understand and interact with the world.
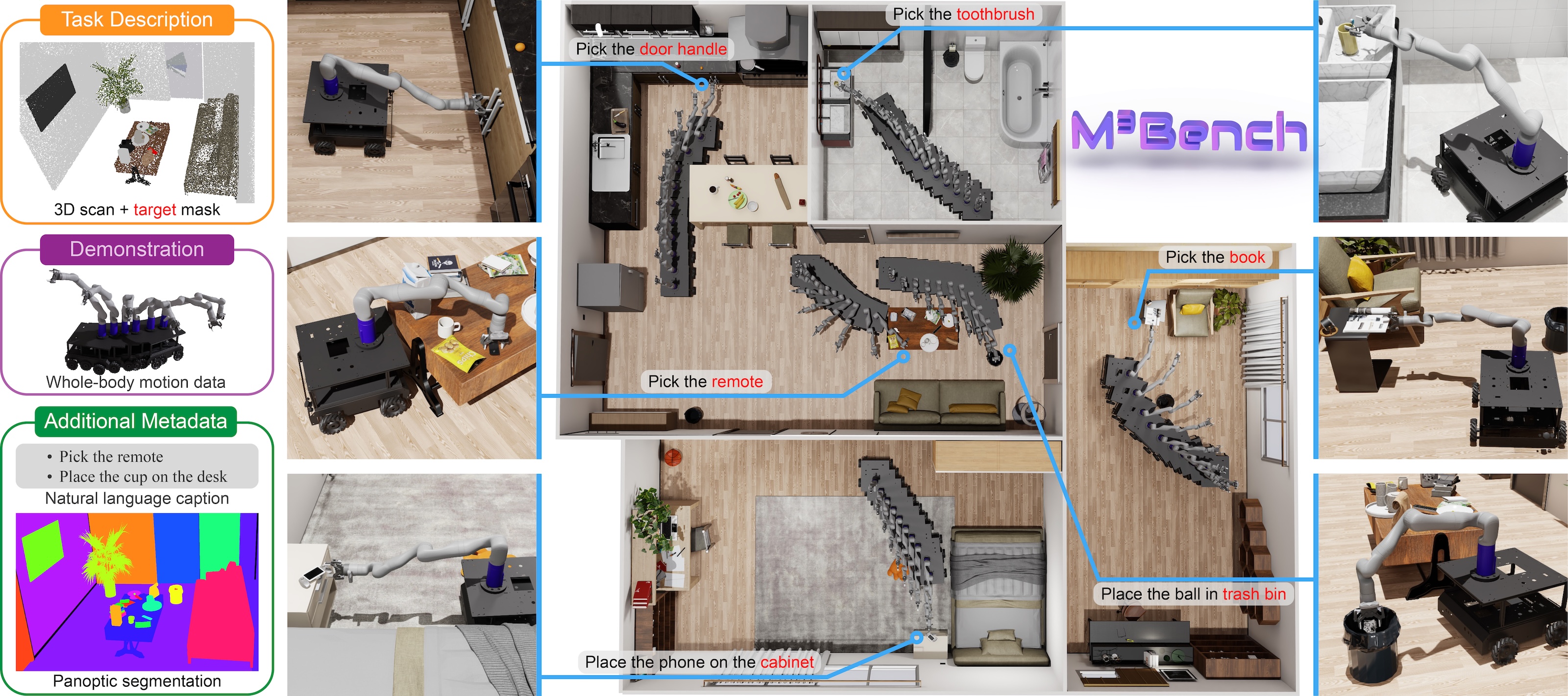
We propose M3Bench, a new benchmark for whole-body motion generation in mobile manipulation tasks. Given a 3D scene context, M3Bench requires an embodied agent to reason about its configuration, environmental constraints, and task objectives to generate coordinated whole-body motion trajectories for object rearrangement. M3Bench features 30,000 object rearrangement tasks across 119 diverse scenes, providing expert demonstrations generated by our newly developed M3BenchMaker, an automatic data generation tool that produces whole-body motion trajectories from high-level task instructions using only basic scene and robot information. Our benchmark includes various task splits to evaluate generalization across different dimensions and leverages realistic physics simulation for trajectory assessment. Extensive evaluation analysis reveals that state-of-the-art models struggle with coordinating base-arm motion while adhering to environmental and task-specific constraints, underscoring the need for new models to bridge this gap. By releasing M3Bench and M3BenchMaker at https://zeyuzhang.com/papers/m3bench, we aim to advance robotics research toward more adaptive and capable mobile manipulation in diverse, real-world environments.
@article{zhang2025m3bench,title={M3Bench: Benchmarking Whole-Body Motion Generation for Mobile Manipulation in 3D Scenes},author={Zhang, Zeyu and Yan, Sixu and Han, Muzhi and Wang, Zaijin and Wang, Xinggang and Zhu, Song-Chun and Liu, Hangxin},journal={IEEE Robotics and Automation Letters (RA-L)},year={2025},publisher={IEEE},dataset={https://huggingface.co/datasets/M3Bench/M3Bench},}
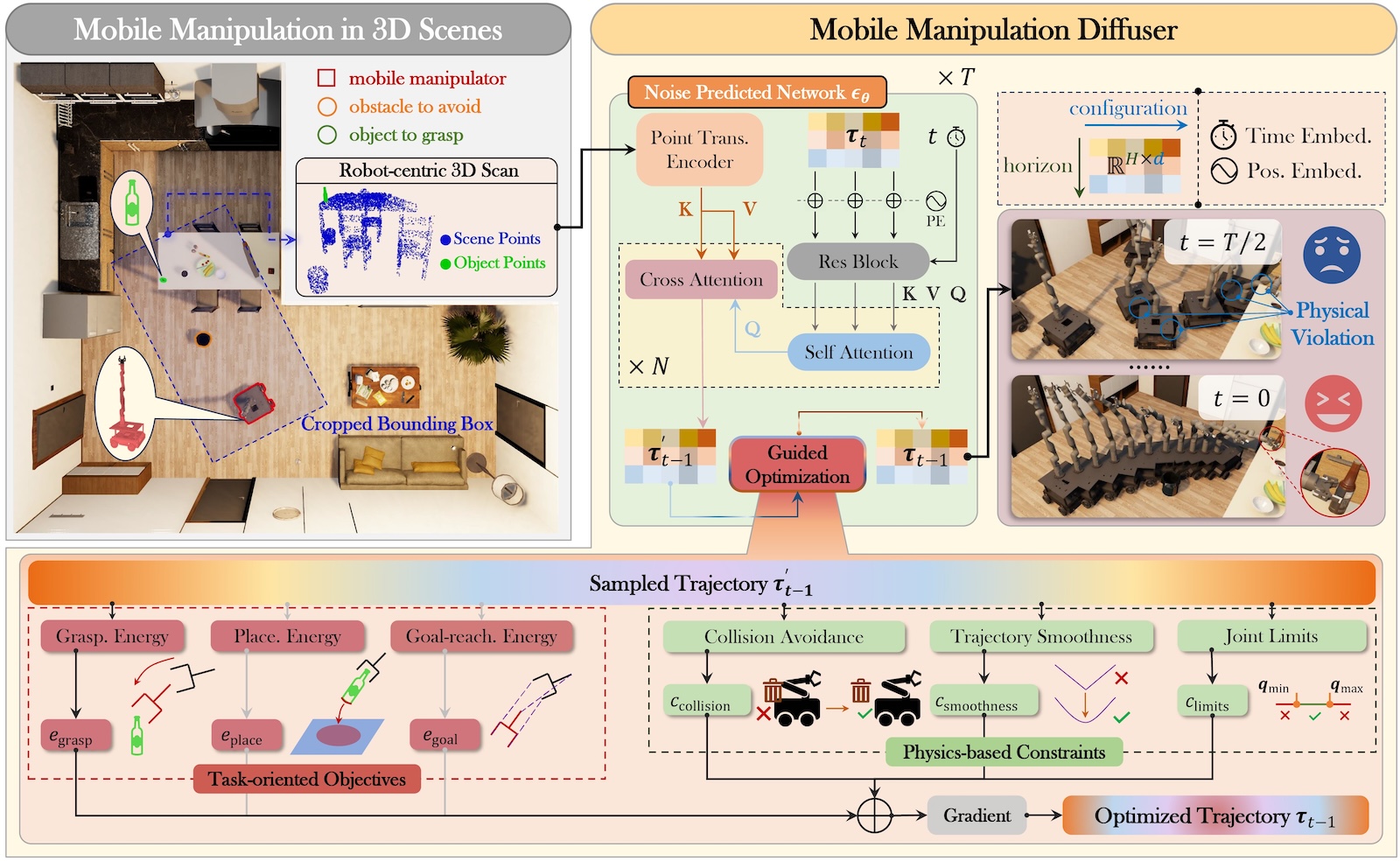
Recent advances in diffusion models have opened new avenues for research into embodied AI agents and robotics. Despite significant achievements in complex robotic locomotion and skills, mobile manipulation-a capability that requires the coordination of navigation and manipulation-remains a challenge for generative AI techniques. This is primarily due to the high-dimensional action space, extended motion trajectories, and interactions with the surrounding environment. In this paper, we introduce M2Diffuser, a diffusion-based, scene-conditioned generative model that directly generates coordinated and efficient whole-body motion trajectories for mobile manipulation based on robot-centric 3D scans. M2Diffuser first learns trajectory-level distributions from mobile manipulation trajectories provided by an expert planner. Crucially, it incorporates an optimization module that can flexibly accommodate physical constraints and task objectives, modeled as cost and energy functions, during the inference process. This enables the reduction of physical violations and execution errors at each denoising step in a fully differentiable manner. Through benchmarking on three types of mobile manipulation tasks across over 20 scenes, we demonstrate that M2Diffuser outperforms state-of-the-art neural planners and successfully transfers the generated trajectories to a real-world robot. Our evaluations underscore the potential of generative AI to enhance the generalization of traditional planning and learning-based robotic methods, while also highlighting the critical role of enforcing physical constraints for safe and robust execution.
@article{yan2025m2diffuser,title={M2Diffuser: Diffusion-based Trajectory Optimization for Mobile Manipulation in 3D Scenes},author={Yan, Sixu and Zhang, Zeyu and Han, Muzhi and Wang, Zaijin and Xie, Qi and Li, Zhitian and Li, Zhehan and Liu, Hangxin and Wang, Xinggang and Zhu, Song-Chun},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI)},year={2025},publisher={IEEE},}
In this work, we present a reconfigurable data glove design to capture different modes of human hand-object interactions, which are critical in training embodied artificial intelligence (AI) agents for fine manipulation tasks. To achieve various downstream tasks with distinct features, our reconfigurable data glove operates in three modes sharing a unified backbone design that reconstructs hand gestures in real time. In the tactile-sensing mode, the glove system aggregates manipulation force via customized force sensors made from a soft and thin piezoresistive material; this design minimizes interference during complex hand movements. The virtual reality (VR) mode enables real-time interaction in a physically plausible fashion: A caging-based approach is devised to determine stable grasps by detecting collision events. Leveraging a state-of-the-art finite element method (FEM), the simulation mode collects data on fine-grained 4D manipulation events comprising hand and object motions in 3D space and how the object’s physical properties (e.g., stress and energy) change in accordance with manipulation over time. Notably, the glove system presented here is the first to use high-fidelity simulation to investigate the unobservable physical and causal factors behind manipulation actions. In a series of experiments, we characterize our data glove in terms of individual sensors and the overall system. More specifically, we evaluate the system’s three modes by (i) recording hand gestures and associated forces, (ii) improving manipulation fluency in VR, and (iii) producing realistic simulation effects of various tool uses, respectively. Based on these three modes, our reconfigurable data glove collects and reconstructs fine-grained human grasp data in both physical and virtual environments, thereby opening up new avenues for the learning of manipulation skills for embodied AI agents.
@article{liu2024reconfigurable,title={A Reconfigurable Data Glove for Reconstructing Physical and Virtual Grasps},author={Liu, Hangxin and Zhang, Zeyu and Jiao, Ziyuan and Zhang, Zhenliang and Li, Minchen and Jiang, Chenfanfu and Zhu, Yixin and Zhu, Song-Chun},journal={Engineering},volume={32},pages={202--216},year={2024},publisher={Elsevier},}
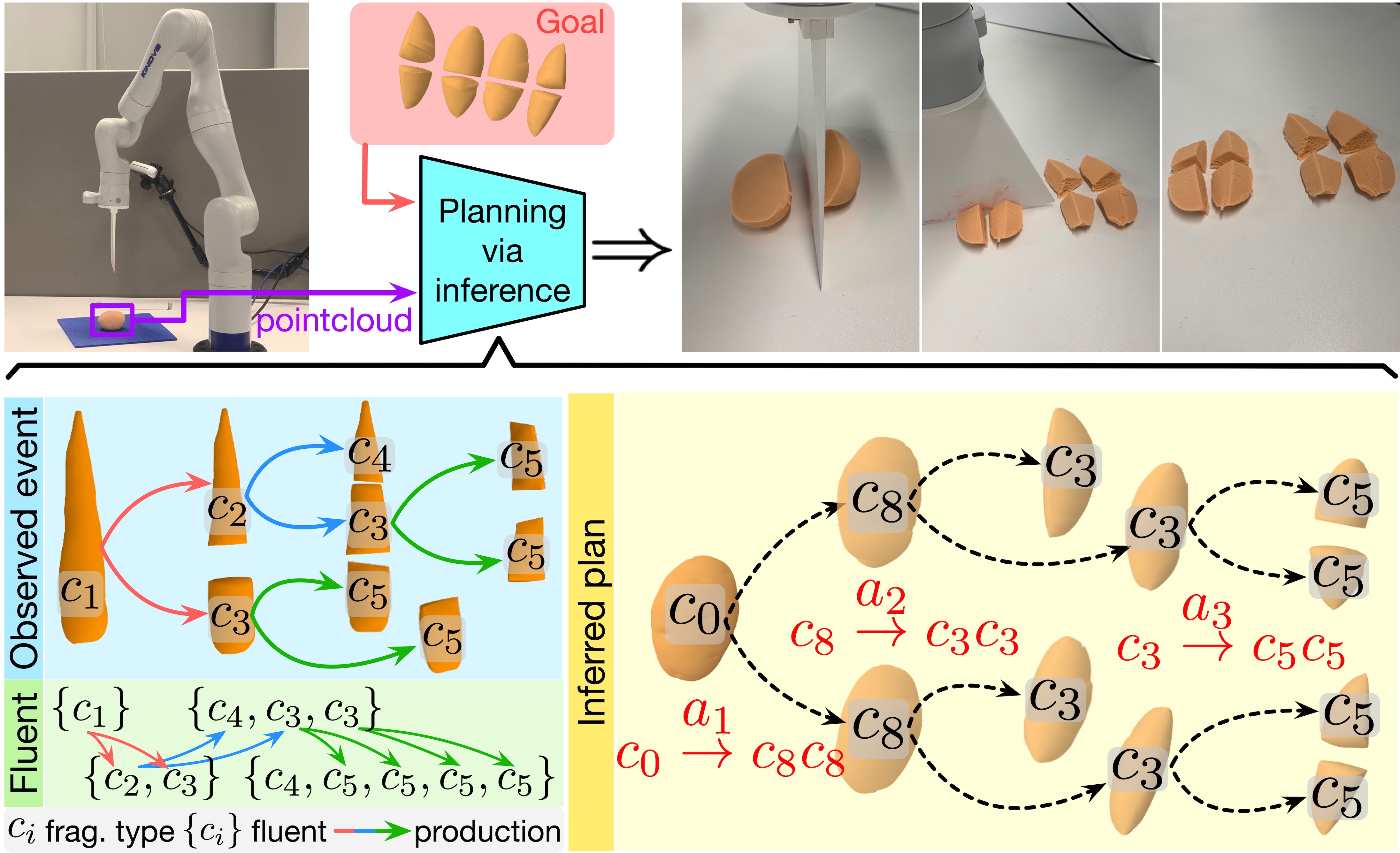
Cutting objects into desired fragments is challenging for robots due to the spatially unstructured nature of fragments and the complex one-to-many object fragmentation caused by actions. We present a novel approach to model object fragmentation using an attributed stochastic grammar. This grammar abstracts fragment states as node variables and captures causal transitions in object fragmentation through production rules. We devise a probabilistic framework to learn this grammar from human demonstrations. The planning process for object cutting involves inferring an optimal parse tree of desired fragments using the learned grammar, with parse tree productions corresponding to cutting actions. We employ Monte Carlo Tree Search (MCTS) to efficiently approximate the optimal parse tree and generate a sequence of executable cutting actions. The experiments demonstrate the efficacy in planning for object-cutting tasks, both in simulation and on a physical robot. The proposed approach outperforms several baselines by demonstrating superior generalization to novel setups, thanks to the compositionality of the grammar model.
@inproceedings{zhang2023learning,title={Learning a Causal Transition Model for Object Cutting},author={Zhang, Zeyu and Han, Muzhi and Jia, Baoxiong and Jiao, Ziyuan and Zhu, Yixin and Zhu, Song-Chun and Liu, Hangxin},booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},pages={1996--2003},year={2023},organization={IEEE},}
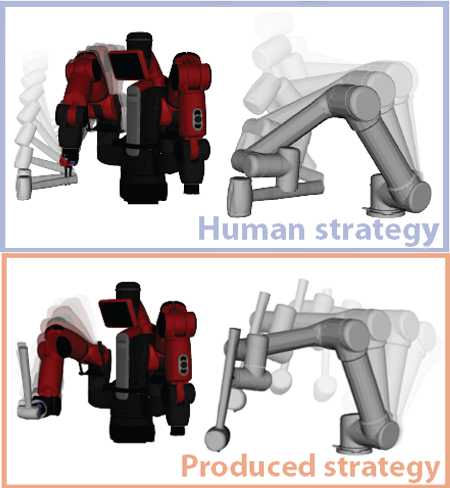
We present a robot learning and planning framework that produces an effective tool-use strategy with the least joint efforts, capable of handling objects different from training. Leveraging a Finite Element Method (FEM)-based simulator that reproduces fine-grained, continuous visual and physical effects given observed tool-use events, the essential physical properties contributing to the effects are identified through the proposed Iterative Deepening Symbolic Regression (IDSR) algorithm. We further devise an optimal control-based motion planning scheme to integrate robot- and tool-specific kinematics and dynamics to produce an effective trajectory that enacts the learned properties. In simulation, we demonstrate that the proposed framework can produce more effective tool-use strategies, drastically different from the observed ones in two exemplar tasks.
@article{zhang2022understanding,title={Understanding Physical Effects for Effective Tool-use},author={Zhang, Zeyu and Jiao, Ziyuan and Wang, Weiqi and Zhu, Yixin and Zhu, Song-Chun and Liu, Hangxin},journal={IEEE Robotics and Automation Letters (RA-L)},volume={7},number={4},pages={9469--9476},year={2022},publisher={IEEE},}
We present a robot learning and planning framework that produces an effective tool-use strategy with the least joint efforts, capable of handling objects different from training. Leveraging a Finite Element Method (FEM)-based simulator that reproduces fine-grained, continuous visual and physical effects given observed tool-use events, the essential physical properties contributing to the effects are identified through the proposed Iterative Deepening Symbolic Regression (IDSR) algorithm. We further devise an optimal control-based motion planning scheme to integrate robot- and tool-specific kinematics and dynamics to produce an effective trajectory that enacts the learned properties. In simulation, we demonstrate that the proposed framework can produce more effective tool-use strategies, drastically different from the observed ones in two exemplar tasks.
@article{han2022scene,title={Scene Reconstruction with Functional Objects for Robot Autonomy},author={Han, Muzhi and Zhang, Zeyu and Jiao, Ziyuan and Xie, Xu and Zhu, Yixin and Zhu, Song-Chun and Liu, Hangxin},journal={International Journal of Computer Vision (IJCV)},volume={130},number={12},pages={2940--2961},year={2022},publisher={Springer},}
If you have any questions, please feel free to contact me via email.