Publication
Pre-Print
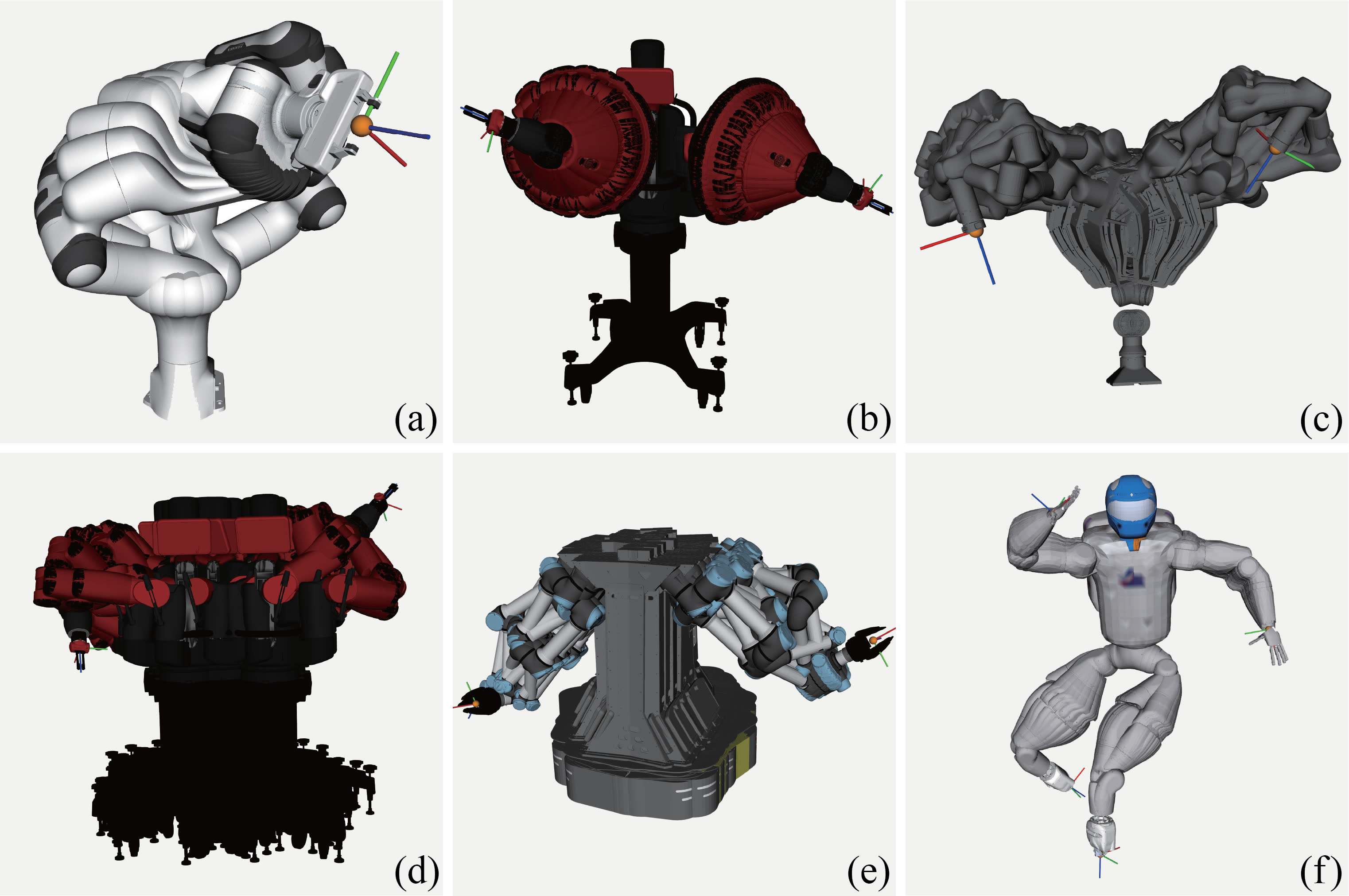
- IKDiffuser: A Generative Inverse Kinematics Solver for Multi-arm Robots via Diffusion Model
ManipulationKinematicsMulti-arm SystemsZeyu Zhang and Ziyuan Jiao†2025Solving Inverse Kinematics (IK) problems is fundamental to robotics, but has primarily been successful with single serial manipulators. For multi-arm robotic systems, IK remains challenging due to complex self-collisions, coupled joints, and high-dimensional redundancy. These complexities make traditional IK solvers slow, prone to failure, and lacking in solution diversity. In this paper, we present IKDiffuser, a diffusion-based model designed for fast and diverse IK solution generation for multi-arm robotic systems. IKDiffuser learns the joint distribution over the configuration space, capturing complex dependencies and enabling seamless generalization to multi-arm robotic systems of different structures. In addition, IKDiffuser can incorporate additional objectives during inference without retraining, offering versatility and adaptability for task-specific requirements. In experiments on 6 different multi-arm systems, the proposed IKDiffuser achieves superior solution accuracy, precision, diversity, and computational efficiency compared to existing solvers. The proposed IKDiffuser framework offers a scalable, unified approach to solving multi-arm IK problems, facilitating the potential of multi-arm robotic systems in real-time manipulation tasks.
@misc{zhang2025ikdiffuser, title = {IKDiffuser: A Generative Inverse Kinematics Solver for Multi-arm Robots via Diffusion Model}, author = {Zhang, Zeyu and Jiao, Ziyuan}, journal = {arXiv preprint arXiv:2506.13087}, year = {2025}, }
All Publications
2025
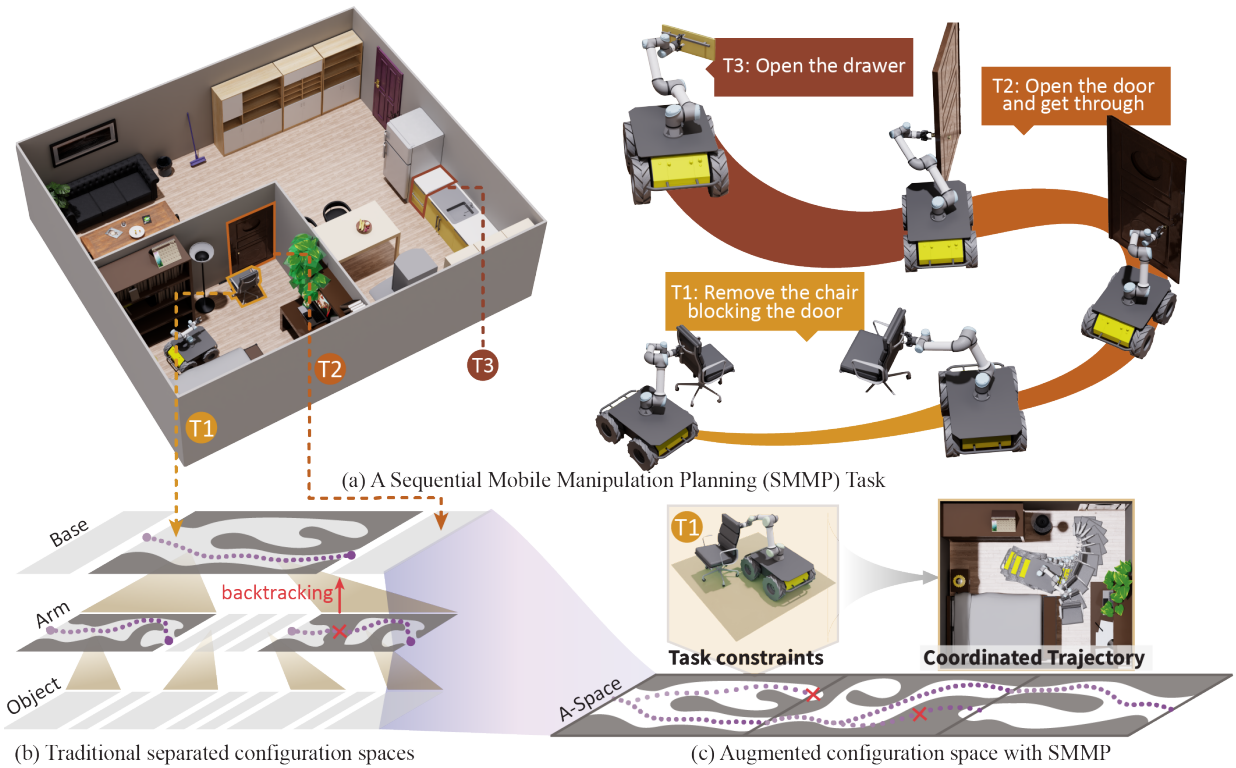
- Integration of Robot and Scene Kinematics for Sequential Mobile Manipulation Planning
ManipulationTAMPIEEE Transactions on Robotics (T-RO), 2025We present a Sequential Mobile Manipulation Planning (SMMP) framework that can solve long-horizon multi-step mobile manipulation tasks with coordinated whole-body motion, even when interacting with articulated objects. By abstracting environmental structures as kinematic models and integrating them with the robot’s kinematics, we construct an Augmented Configuration Apace (A-Space) that unifies the previously separate task constraints for navigation and manipulation, while accounting for the joint reachability of the robot base, arm, and manipulated objects. This integration facilitates efficient planning within a tri-level framework: a task planner generates symbolic action sequences to model the evolution of A-Space, an optimization-based motion planner computes continuous trajectories within A-Space to achieve desired configurations for both the robot and scene elements, and an intermediate plan refinement stage selects action goals that ensure long-horizon feasibility. Our simulation studies first confirm that planning in A-Space achieves an 84.6% higher task success rate compared to baseline methods. Validation on real robotic systems demonstrates fluid mobile manipulation involving (i) seven types of rigid and articulated objects across 17 distinct contexts, and (ii) long-horizon tasks of up to 14 sequential steps. Our results highlight the significance of modeling scene kinematics into planning entities, rather than encoding task-specific constraints, offering a scalable and generalizable approach to complex robotic manipulation.
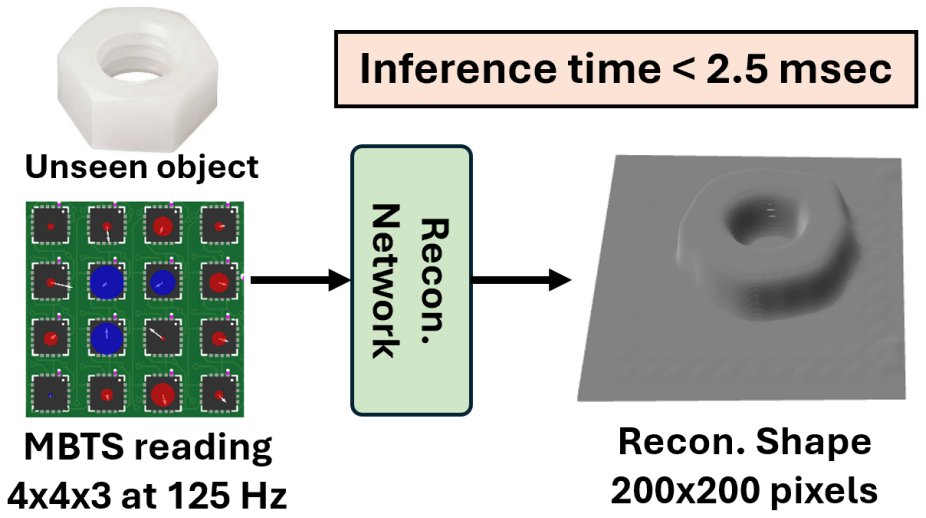
@article{jiao2025integration, title = {Integration of Robot and Scene Kinematics for Sequential Mobile Manipulation Planning}, author = {Jiao, Ziyuan and Niu, Yida and Zhang, Zeyu and Wu, Yangyang and Su, Yao and Zhu, Yixin and Liu, Hangxin and Zhu, Song-Chun}, journal = {IEEE Transactions on Robotics (T-RO)}, year = {2025}, publisher = {IEEE}, } - SuperMag: Vision-based Tactile Data Guided High-resolution Tactile Shape Reconstruction for Magnetic Tactile Sensors
TactilePeiyao Hou*, Danning Sun*, Meng Wang, Yuzhe Huang, Zeyu Zhang, Hangxin Liu, Wanlin Li†, and Ziyuan Jiao†In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025Magnetic-based tactile sensors (MBTS) combine the advantages of compact design and high-frequency operation but suffer from limited spatial resolution due to their sparse taxel arrays. This paper proposes SuperMag, a tactile shape reconstruction method that addresses this limitation by leveraging high-resolution vision-based tactile sensor (VBTS) data to supervise MBTS super-resolution. Co-designed, open-source VBTS and MBTS with identical contact modules enable synchronized data collection of high-resolution shapes and magnetic signals via a symmetric calibration setup. We frame tactile shape reconstruction as a conditional generative problem, employing a conditional variational auto-encoder to infer high-resolution shapes from low-resolution MBTS inputs. The MBTS achieves a sampling frequency of 125 Hz, whereas the shape reconstruction sustains an inference time within 2.5 ms. This cross-modality synergy advances tactile perception of the MBTS, potentially unlocking its new capabilities in high-precision robotic tasks.
@inproceedings{hou2025supermag, title = {SuperMag: Vision-based Tactile Data Guided High-resolution Tactile Shape Reconstruction for Magnetic Tactile Sensors}, author = {Hou, Peiyao and Sun, Danning and Wang, Meng and Huang, Yuzhe and Zhang, Zeyu and Liu, Hangxin and Li, Wanlin and Jiao, Ziyuan}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2025}, organization = {IEEE}, } - T-CE
 A VR-Based Robotic Teleoperation System With Haptic Feedback and Adaptive Collision Avoidance
A VR-Based Robotic Teleoperation System With Haptic Feedback and Adaptive Collision AvoidanceTeleoperationTactileManipulationFan Wu*, Ziyuan Jiao*†, Wanlin Li*†, Zeyu Zhang*, Hang Li, Jiahao Wu, Baoxiong Jia, and Shaopeng DongIEEE Transactions on Consumer Electronics (T-CE), 2025Robotic teleoperation systems enable humans to control robots remotely. Recent advancements in VR have transformed teleoperation into immersive, intuitive platforms that improve human-machine synergy. However, existing VR-based teleoperation systems face challenges such as under-informed shared control, limited tactile feedback, and computational inefficiencies, which hinder their effectiveness in complex, cluttered scenarios. This paper introduces a novel VR-based teleoperation system incorporating haptic feedback and adaptive collision avoidance. The system tracks human hand trajectories via an VR-based handheld device and provides tactile feedback from a robotic gripper. Through the proposed tele-MPPI method, the system anticipates robot motions, adaptively adjusts trajectories to avoid obstacles, and maintains computational efficiency, enabling real-time operation at 20 Hz. Simulations and experiments demonstrate the system’s ability to grasp delicate objects without damage and to navigate cluttered environments by mitigating collision risks.
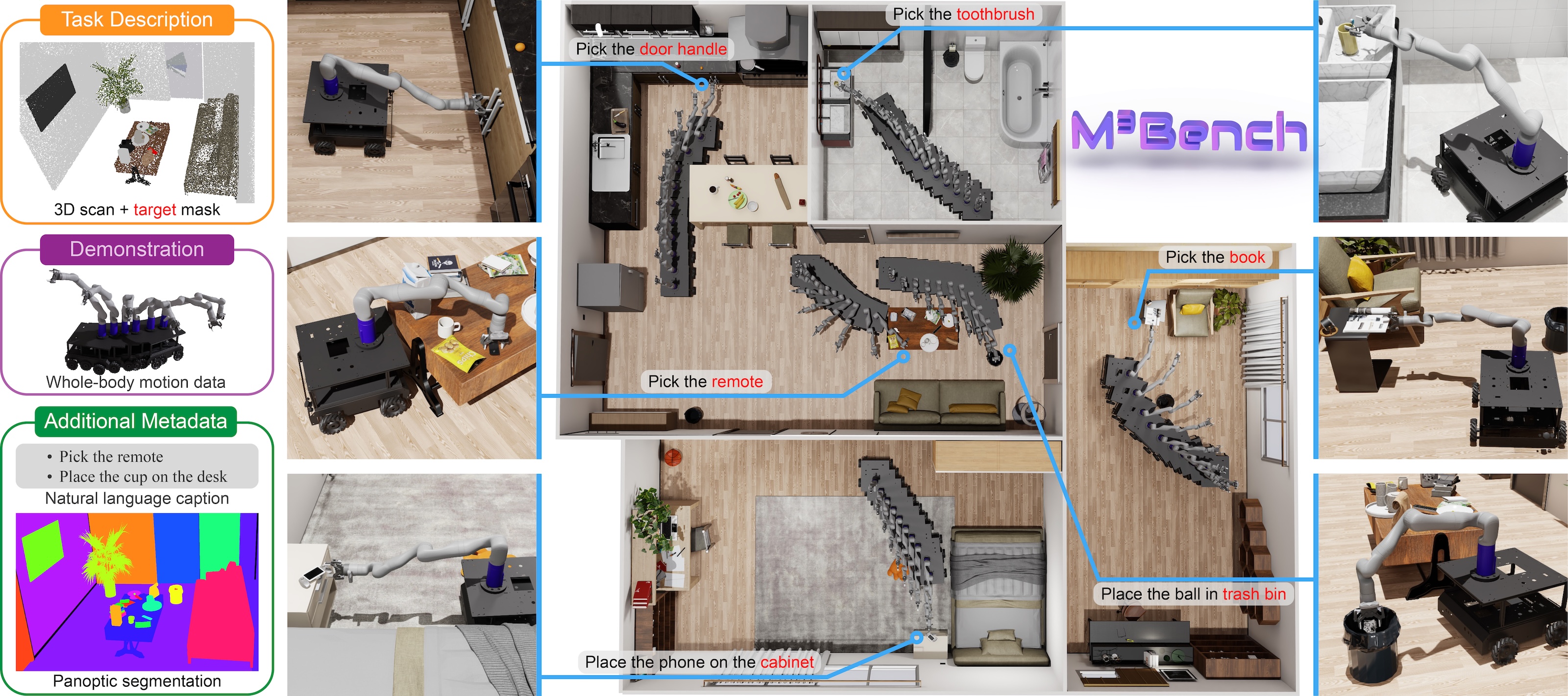
@article{wu2025vr, title = {A VR-Based Robotic Teleoperation System With Haptic Feedback and Adaptive Collision Avoidance}, author = {Wu, Fan and Jiao, Ziyuan and Li, Wanlin and Zhang, Zeyu and Li, Hang and Wu, Jiahao and Jia, Baoxiong and Dong, Shaopeng}, journal = {IEEE Transactions on Consumer Electronics (T-CE)}, year = {2025}, publisher = {IEEE}, } - M3Bench: Benchmarking Whole-Body Motion Generation for Mobile Manipulation in 3D Scenes
Mobile ManipulationMotion GenerationBenchmarkIEEE Robotics and Automation Letters (RA-L), 2025We propose M3Bench, a new benchmark for whole-body motion generation in mobile manipulation tasks. Given a 3D scene context, M3Bench requires an embodied agent to reason about its configuration, environmental constraints, and task objectives to generate coordinated whole-body motion trajectories for object rearrangement. M3Bench features 30,000 object rearrangement tasks across 119 diverse scenes, providing expert demonstrations generated by our newly developed M3BenchMaker, an automatic data generation tool that produces whole-body motion trajectories from high-level task instructions using only basic scene and robot information. Our benchmark includes various task splits to evaluate generalization across different dimensions and leverages realistic physics simulation for trajectory assessment. Extensive evaluation analysis reveals that state-of-the-art models struggle with coordinating base-arm motion while adhering to environmental and task-specific constraints, underscoring the need for new models to bridge this gap. By releasing M3Bench and M3BenchMaker at https://zeyuzhang.com/papers/m3bench, we aim to advance robotics research toward more adaptive and capable mobile manipulation in diverse, real-world environments.
@article{zhang2025m3bench, title = {M3Bench: Benchmarking Whole-Body Motion Generation for Mobile Manipulation in 3D Scenes}, author = {Zhang, Zeyu and Yan, Sixu and Han, Muzhi and Wang, Zaijin and Wang, Xinggang and Zhu, Song-Chun and Liu, Hangxin}, journal = {IEEE Robotics and Automation Letters (RA-L)}, year = {2025}, publisher = {IEEE}, dataset = {https://huggingface.co/datasets/M3Bench/M3Bench}, } - M2Diffuser: Diffusion-based Trajectory Optimization for Mobile Manipulation in 3D Scenes
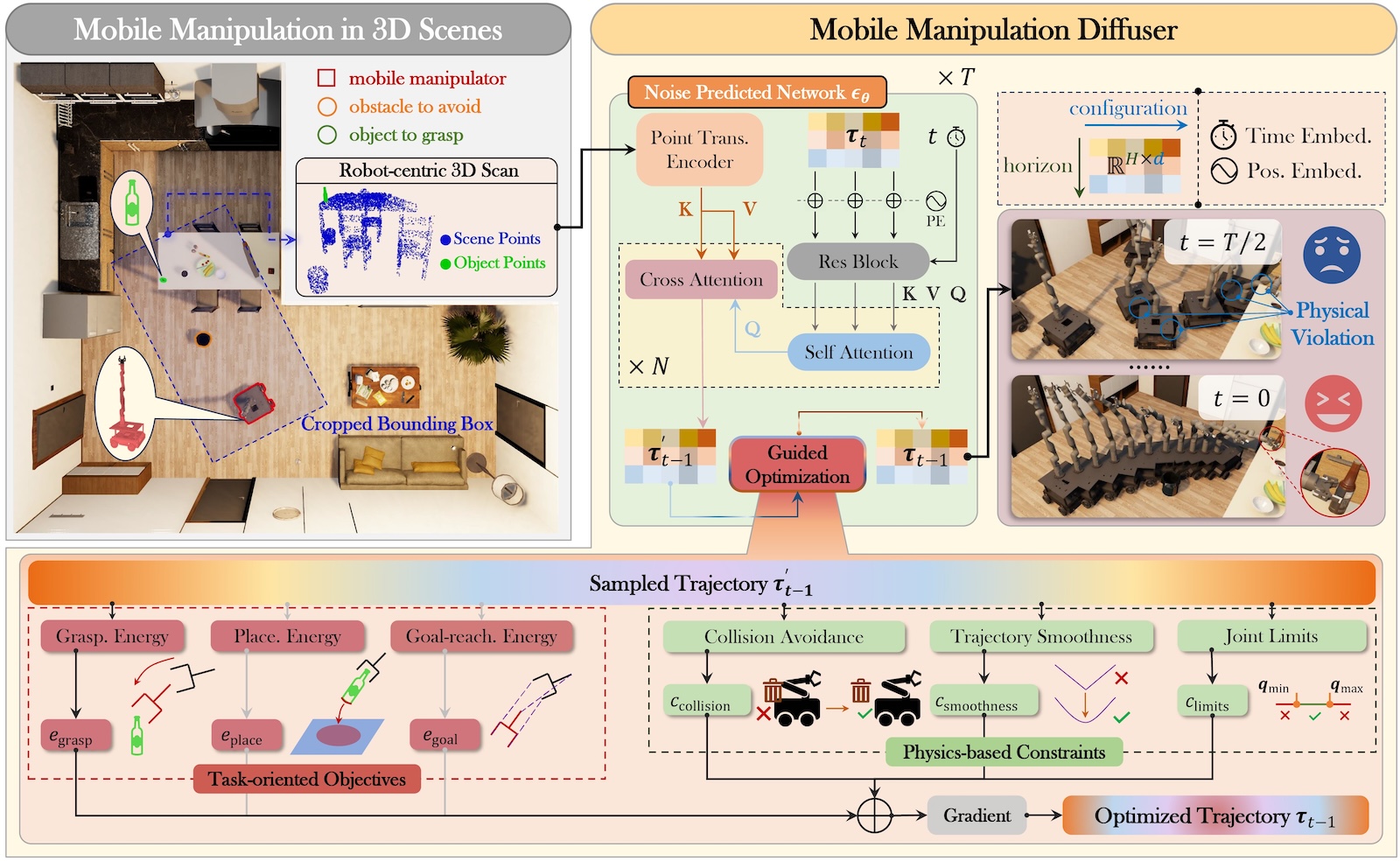
Mobile ManipulationMotion GenerationTrajectory OptimizationSixu Yan, Zeyu Zhang, Muzhi Han, Zaijin Wang, Qi Xie, Zhitian Li, Zhehan Li, Hangxin Liu†, Xinggang Wang†, and Song-Chun ZhuIEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2025Recent advances in diffusion models have opened new avenues for research into embodied AI agents and robotics. Despite significant achievements in complex robotic locomotion and skills, mobile manipulation-a capability that requires the coordination of navigation and manipulation-remains a challenge for generative AI techniques. This is primarily due to the high-dimensional action space, extended motion trajectories, and interactions with the surrounding environment. In this paper, we introduce M2Diffuser, a diffusion-based, scene-conditioned generative model that directly generates coordinated and efficient whole-body motion trajectories for mobile manipulation based on robot-centric 3D scans. M2Diffuser first learns trajectory-level distributions from mobile manipulation trajectories provided by an expert planner. Crucially, it incorporates an optimization module that can flexibly accommodate physical constraints and task objectives, modeled as cost and energy functions, during the inference process. This enables the reduction of physical violations and execution errors at each denoising step in a fully differentiable manner. Through benchmarking on three types of mobile manipulation tasks across over 20 scenes, we demonstrate that M2Diffuser outperforms state-of-the-art neural planners and successfully transfers the generated trajectories to a real-world robot. Our evaluations underscore the potential of generative AI to enhance the generalization of traditional planning and learning-based robotic methods, while also highlighting the critical role of enforcing physical constraints for safe and robust execution.
@article{yan2025m2diffuser, title = {M2Diffuser: Diffusion-based Trajectory Optimization for Mobile Manipulation in 3D Scenes}, author = {Yan, Sixu and Zhang, Zeyu and Han, Muzhi and Wang, Zaijin and Xie, Qi and Li, Zhitian and Li, Zhehan and Liu, Hangxin and Wang, Xinggang and Zhu, Song-Chun}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI)}, year = {2025}, publisher = {IEEE}, } - Closed-loop Open-vocabulary Mobile Manipulation with GPT-4v
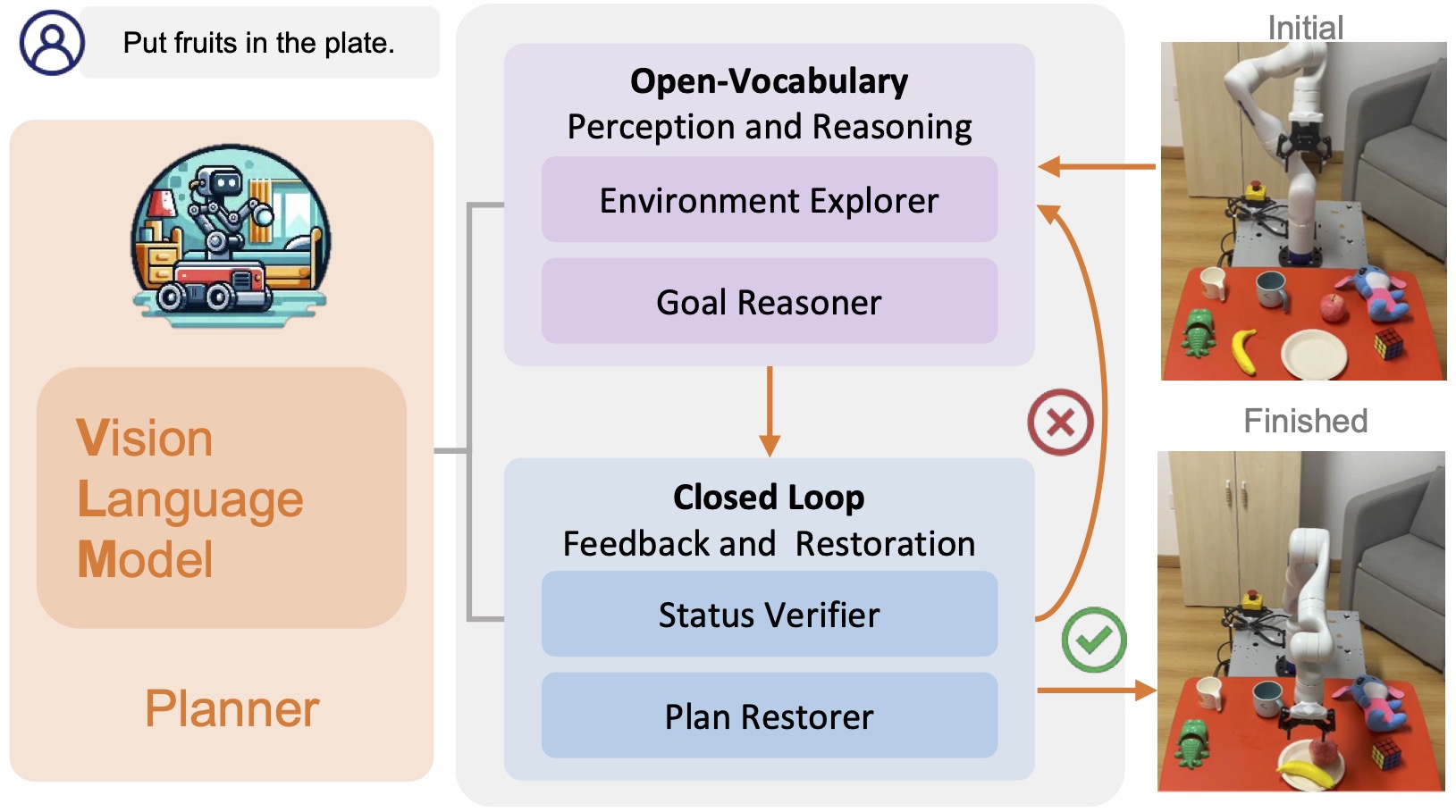
ManipulationLLMPeiyuan Zhi*, Zhiyuan Zhang*, Yu Zhao, Muzhi Han, Zeyu Zhang, Zhitian Li, Ziyuan Jiao, Baoxiong Jia†, and Siyuan Huang†In IEEE International Conference on Robotics and Automation (ICRA), 2025Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. In this work, we present COME-robot, the first closed-loop robotic system utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios. robot incorporates two key innovative modules: (i) a multi-level open-vocabulary perception and situated reasoning module that enables effective exploration of the 3D environment and target object identification using commonsense knowledge and situated information, and (ii) an iterative closed-loop feedback and restoration mechanism that verifies task feasibility, monitors execution success, and traces failure causes across different modules for robust failure recovery. Through comprehensive experiments involving 8 challenging real-world mobile and tabletop manipulation tasks, COME-robot demonstrates a significant improvement in task success rate ( 35%) compared to state-of-the-art methods. We further conduct comprehensive analyses to elucidate how COME-robot’s design facilitates failure recovery, free-form instruction following, and long-horizon task planning.
@inproceedings{zhi2024closed, title = {Closed-loop Open-vocabulary Mobile Manipulation with GPT-4v}, author = {Zhi, Peiyuan and Zhang, Zhiyuan and Zhao, Yu and Han, Muzhi and Zhang, Zeyu and Li, Zhitian and Jiao, Ziyuan and Jia, Baoxiong and Huang, Siyuan}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, year = {2025}, organization = {IEEE}, } - PR2: A Physics-and Photo-realistic Testbed for Embodied AI and Humanoid Robots
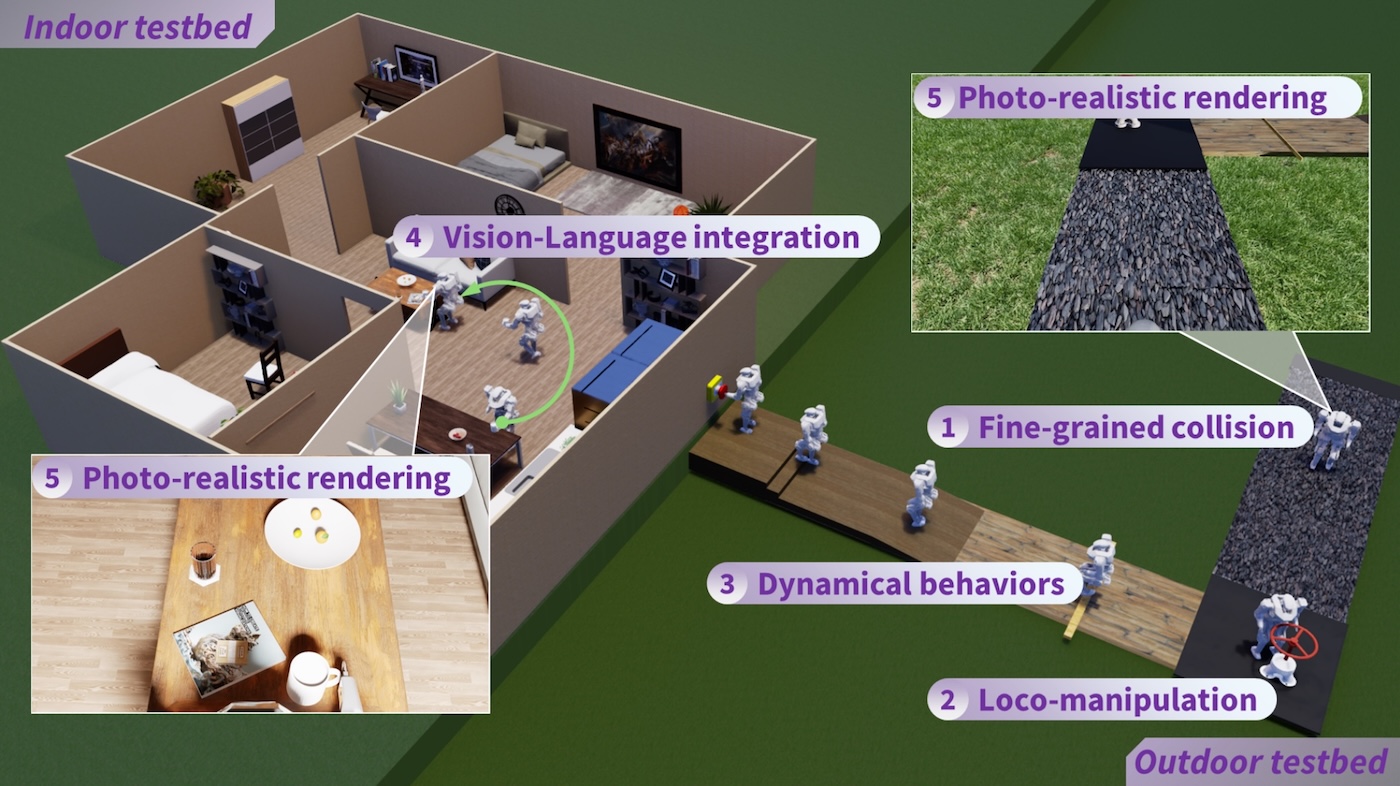
ManipulationHumanoidLoco-manipulationHangxin Liu, Qi Xie, Zeyu Zhang, Tao Yuan, Xiaokun Leng, Lining Sun, Song-Chun Zhu, Jingwen Zhang†, Zhicheng He†, and Yao Su†Journal of Field Robotics, 2025This paper presents the development of a Physics-realistic and Photo-realistic humanoid robot testbed, PR2, to facilitate collaborative research between Embodied Artificial Intelligence (Embodied AI) and robotics. PR2 offers high-quality scene rendering and robot dynamic simulation, enabling (i) the creation of diverse scenes using various digital assets, (ii) the integration of advanced perception or foundation models, and (iii) the implementation of planning and control algorithms for dynamic humanoid robot behaviors based on environmental feedback. The beta version of PR2 has been deployed for the simulation track of a nationwide full-size humanoid robot competition for college students, attracting 137 teams and over 400 participants within four months. This competition covered traditional tasks in bipedal walking, as well as novel challenges in loco-manipulation and language-instruction-based object search, marking a first for public college robotics competitions. A retrospective analysis of the competition suggests that future events should emphasize the integration of locomotion with manipulation and perception. By making the PR2 testbed publicly, we aim to further advance education and training in humanoid robotics.
@article{liu2024pr2, title = {PR2: A Physics-and Photo-realistic Testbed for Embodied AI and Humanoid Robots}, author = {Liu, Hangxin and Xie, Qi and Zhang, Zeyu and Yuan, Tao and Leng, Xiaokun and Sun, Lining and Zhu, Song-Chun and Zhang, Jingwen and He, Zhicheng and Su, Yao}, journal = {Journal of Field Robotics}, doi = {https://doi.org/10.1002/rob.22588}, year = {2025}, }
2024
- A Reconfigurable Data Glove for Reconstructing Physical and Virtual Grasps
ManipulationToolTactileHangxin Liu*†, Zeyu Zhang*, Ziyuan Jiao*, Zhenliang Zhang, Minchen Li, Chenfanfu Jiang, Yixin Zhu†, and Song-Chun ZhuEngineering, 2024In this work, we present a reconfigurable data glove design to capture different modes of human hand-object interactions, which are critical in training embodied artificial intelligence (AI) agents for fine manipulation tasks. To achieve various downstream tasks with distinct features, our reconfigurable data glove operates in three modes sharing a unified backbone design that reconstructs hand gestures in real time. In the tactile-sensing mode, the glove system aggregates manipulation force via customized force sensors made from a soft and thin piezoresistive material; this design minimizes interference during complex hand movements. The virtual reality (VR) mode enables real-time interaction in a physically plausible fashion: A caging-based approach is devised to determine stable grasps by detecting collision events. Leveraging a state-of-the-art finite element method (FEM), the simulation mode collects data on fine-grained 4D manipulation events comprising hand and object motions in 3D space and how the object’s physical properties (e.g., stress and energy) change in accordance with manipulation over time. Notably, the glove system presented here is the first to use high-fidelity simulation to investigate the unobservable physical and causal factors behind manipulation actions. In a series of experiments, we characterize our data glove in terms of individual sensors and the overall system. More specifically, we evaluate the system’s three modes by (i) recording hand gestures and associated forces, (ii) improving manipulation fluency in VR, and (iii) producing realistic simulation effects of various tool uses, respectively. Based on these three modes, our reconfigurable data glove collects and reconstructs fine-grained human grasp data in both physical and virtual environments, thereby opening up new avenues for the learning of manipulation skills for embodied AI agents.
@article{liu2024reconfigurable, title = {A Reconfigurable Data Glove for Reconstructing Physical and Virtual Grasps}, author = {Liu, Hangxin and Zhang, Zeyu and Jiao, Ziyuan and Zhang, Zhenliang and Li, Minchen and Jiang, Chenfanfu and Zhu, Yixin and Zhu, Song-Chun}, journal = {Engineering}, volume = {32}, pages = {202--216}, year = {2024}, publisher = {Elsevier}, } - On the Emergence of Symmetrical Reality
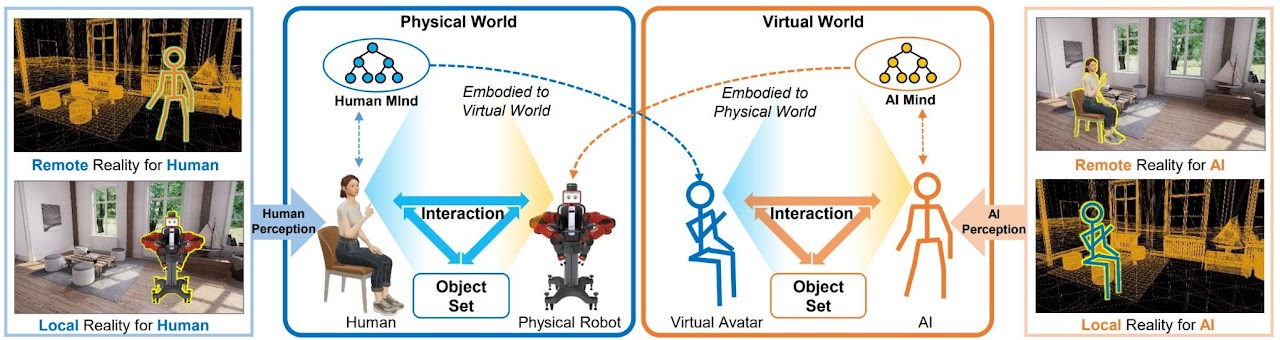
VRARTeamingIn IEEE Conference Virtual Reality and 3D User Interfaces (VR), 2024Artificial intelligence (AI) has revolutionized human cognitive abilities and facilitated the development of new AI entities capable of interacting with humans in both physical and virtual environments. Despite the existence of virtual reality, mixed reality, and augmented reality for several years, integrating these technical fields remains a formidable challenge due to their disparate application directions. The advent of AI agents, capable of autonomous perception and action, further compounds this issue by exposing the limitations of traditional human-centered research approaches. It is imperative to establish a comprehensive framework that accommodates the dual perceptual centers of humans and AI agents in both physical and virtual worlds. In this paper, we introduce the symmetrical reality framework, which offers a unified representation encompassing various forms of physical-virtual amalgamations. This framework enables researchers to better comprehend how AI agents can collaborate with humans and how distinct technical pathways of physical-virtual integration can be consolidated from a broader perspective. We then delve into the coexistence of humans and AI, demonstrating a prototype system that exemplifies the operation of symmetrical reality systems for specific tasks, such as pouring water. Subsequently, we propose an instance of an AI-driven active assistance service that illustrates the potential applications of symmetrical reality. This paper aims to offer beneficial perspectives and guidance for researchers and practitioners in different fields, thus contributing to the ongoing research about human-AI coexistence in both physical and virtual environments.
@inproceedings{zhang2024emergence, title = {On the Emergence of Symmetrical Reality}, author = {Zhang, Zhenliang and Zhang, Zeyu and Jiao, Ziyuan and Su, Yao and Liu, Hangxin and Wang, Wei and Zhu, Song-Chun}, booktitle = {IEEE Conference Virtual Reality and 3D User Interfaces (VR)}, pages = {639--649}, year = {2024}, organization = {IEEE}, } - Flight Structure Optimization of Modular Reconfigurable UAVs
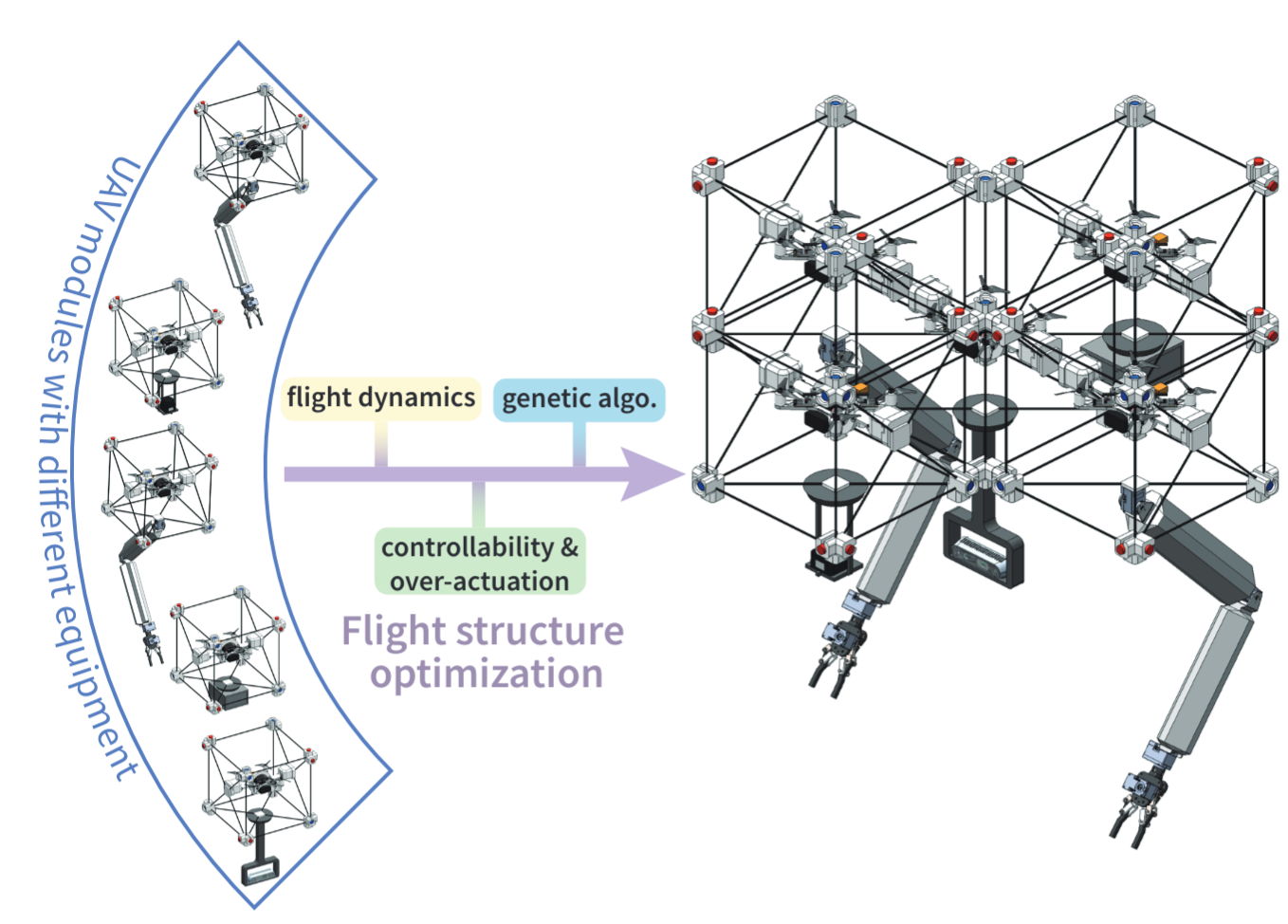
OptimizationIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024This paper presents a Genetic Algorithm (GA) designed to reconfigure a large group of modular Unmanned Aerial Vehicles (UAVs), each with different weights and inertia parameters, into an over-actuated flight structure with improved dynamic properties. Previous research efforts either utilized expert knowledge to design flight structures for a specific task or relied on enumeration-based algorithms that required extensive computation to find an optimal one. However, both approaches encounter challenges in accommodating the heterogeneity among modules. Our GA addresses these challenges by incorporating the complexities of over-actuation and dynamic properties into its formulation. Additionally, we employ a tree representation and a vector representation to describe flight structures, facilitating efficient crossover operations and fitness evaluations within the GA framework, respectively. Using cubic modular quadcopters capable of functioning as omni-directional thrust generators, we validate that the proposed approach can (i) adeptly identify suboptimal configurations ensuring over-actuation while ensuring trajectory tracking accuracy and (ii) significantly reduce computational costs compared to traditional enumeration-based methods.
@inproceedings{su2024flight, title = {Flight Structure Optimization of Modular Reconfigurable UAVs}, author = {Su, Yao and Jiao, Ziyuan and Zhang, Zeyu and Zhang, Jingwen and Li, Hang and Wang, Meng and Liu, Hangxin}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {4556--4562}, year = {2024}, organization = {IEEE}, } - LLM3: Large Language Model-based Task and Motion Planning with Motion Failure Reasoning
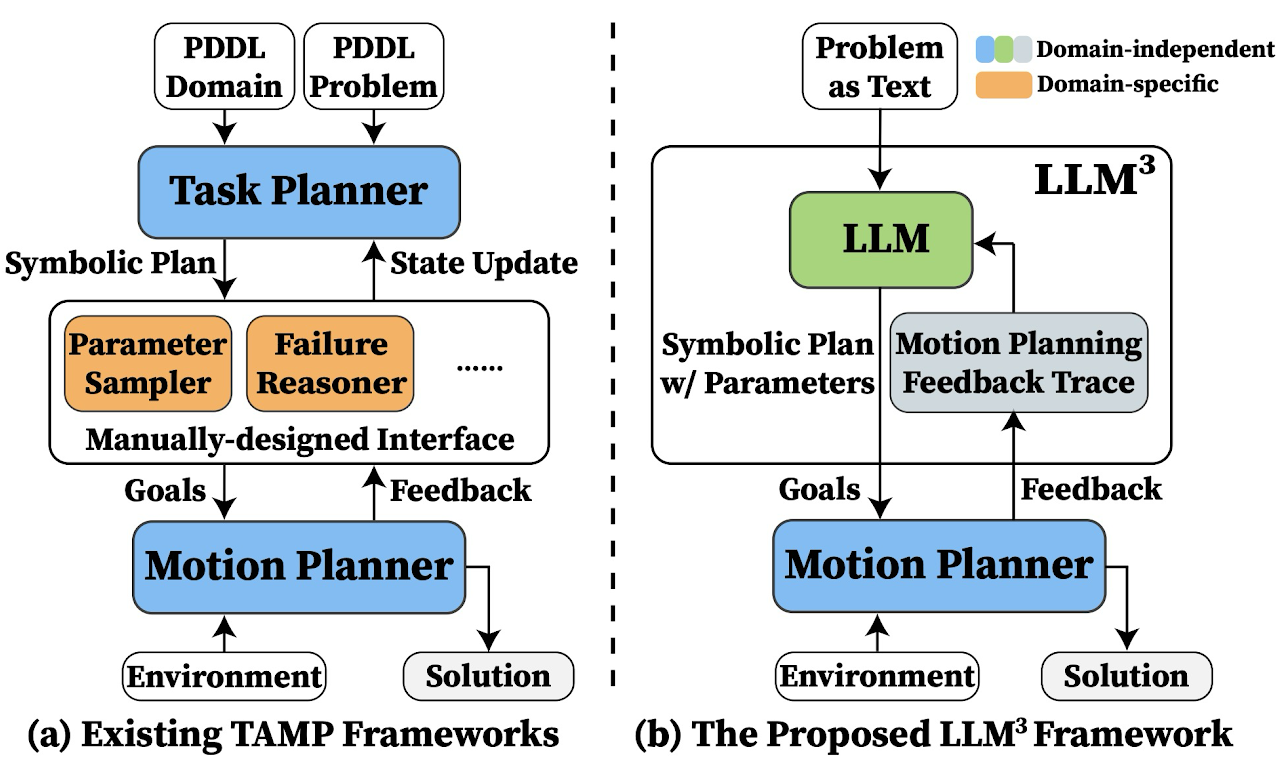
LLMTAMPManipulationIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024Conventional Task and Motion Planning (TAMP) approaches rely on manually crafted interfaces connecting symbolic task planning with continuous motion generation. These domain-specific and labor-intensive modules are limited in addressing emerging tasks in real-world settings. Here, we present LLM^3, a novel Large Language Model (LLM)-based TAMP framework featuring a domain-independent interface. Specifically, we leverage the powerful reasoning and planning capabilities of pre-trained LLMs to propose symbolic action sequences and select continuous action parameters for motion planning. Crucially, LLM^3 incorporates motion planning feedback through prompting, allowing the LLM to iteratively refine its proposals by reasoning about motion failure. Consequently, LLM^3 interfaces between task planning and motion planning, alleviating the intricate design process of handling domain-specific messages between them. Through a series of simulations in a box-packing domain, we quantitatively demonstrate the effectiveness of LLM^3 in solving TAMP problems and the efficiency in selecting action parameters. Ablation studies underscore the significant contribution of motion failure reasoning to the success of LLM^3. Furthermore, we conduct qualitative experiments on a physical manipulator, demonstrating the practical applicability of our approach in real-world settings.
@inproceedings{wang2024llm3, title = {LLM3: Large Language Model-based Task and Motion Planning with Motion Failure Reasoning}, author = {Wang, Shu and Han, Muzhi and Jiao, Ziyuan and Zhang, Zeyu and Wu, Ying Nian and Zhu, Song-Chun and Liu, Hangxin}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {12086--12092}, year = {2024}, organization = {IEEE}, }

2023
- Part-level Scene Reconstruction Affords Robot Interaction
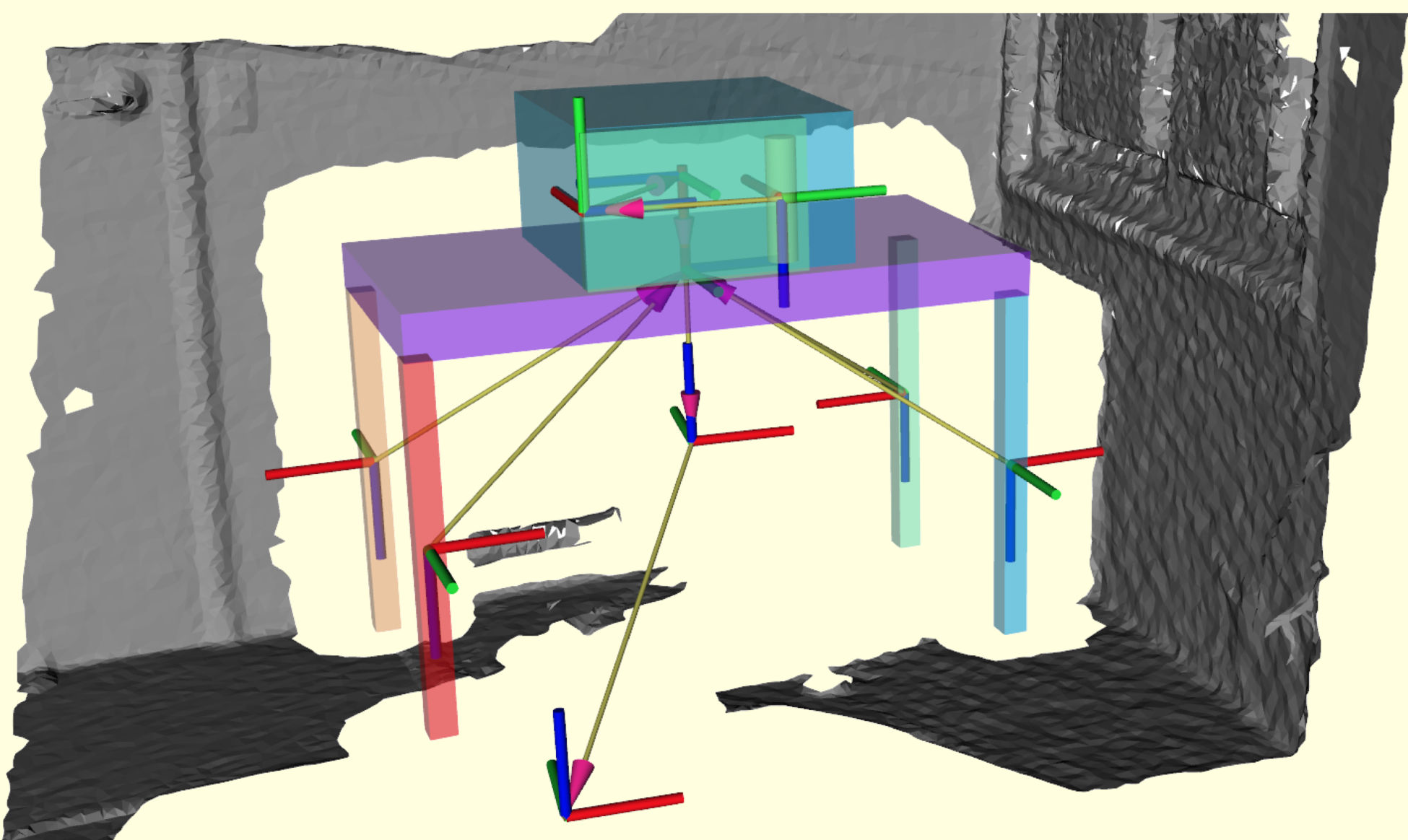
Scene ReconstructionAffordanceDigital TwinZeyu Zhang*, Lexing Zhang*, Zaijin Wang, Ziyuan Jiao, Muzhi Han, Yixin Zhu, Song-Chun Zhu, and Hangxin Liu†In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023Existing methods for reconstructing interactive scenes primarily focus on replacing reconstructed objects with CAD models retrieved from a limited database, resulting in significant discrepancies between the reconstructed and observed scenes. To address this issue, our work introduces a part-level reconstruction approach that reassembles objects using primitive shapes. This enables us to precisely replicate the observed physical scenes and simulate robot interactions with both rigid and articulated objects. By segmenting reconstructed objects into semantic parts and aligning primitive shapes to these parts, we assemble them as CAD models while estimating kinematic relations, including parent-child contact relations, joint types, and parameters. Specifically, we derive the optimal primitive alignment by solving a series of optimization problems, and estimate kinematic relations based on part semantics and geometry. Our experiments demonstrate that part-level scene reconstruction outperforms object-level reconstruction by accurately capturing finer details and improving precision. These reconstructed part-level interactive scenes provide valuable kinematic information for various robotic applications; we showcase the feasibility of certifying mobile manipulation planning in these interactive scenes before executing tasks in the physical world.
@inproceedings{zhang2023part, title = {Part-level Scene Reconstruction Affords Robot Interaction}, author = {Zhang, Zeyu and Zhang, Lexing and Wang, Zaijin and Jiao, Ziyuan and Han, Muzhi and Zhu, Yixin and Zhu, Song-Chun and Liu, Hangxin}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {11178--11185}, year = {2023}, organization = {IEEE}, } - Learning a Causal Transition Model for Object Cutting
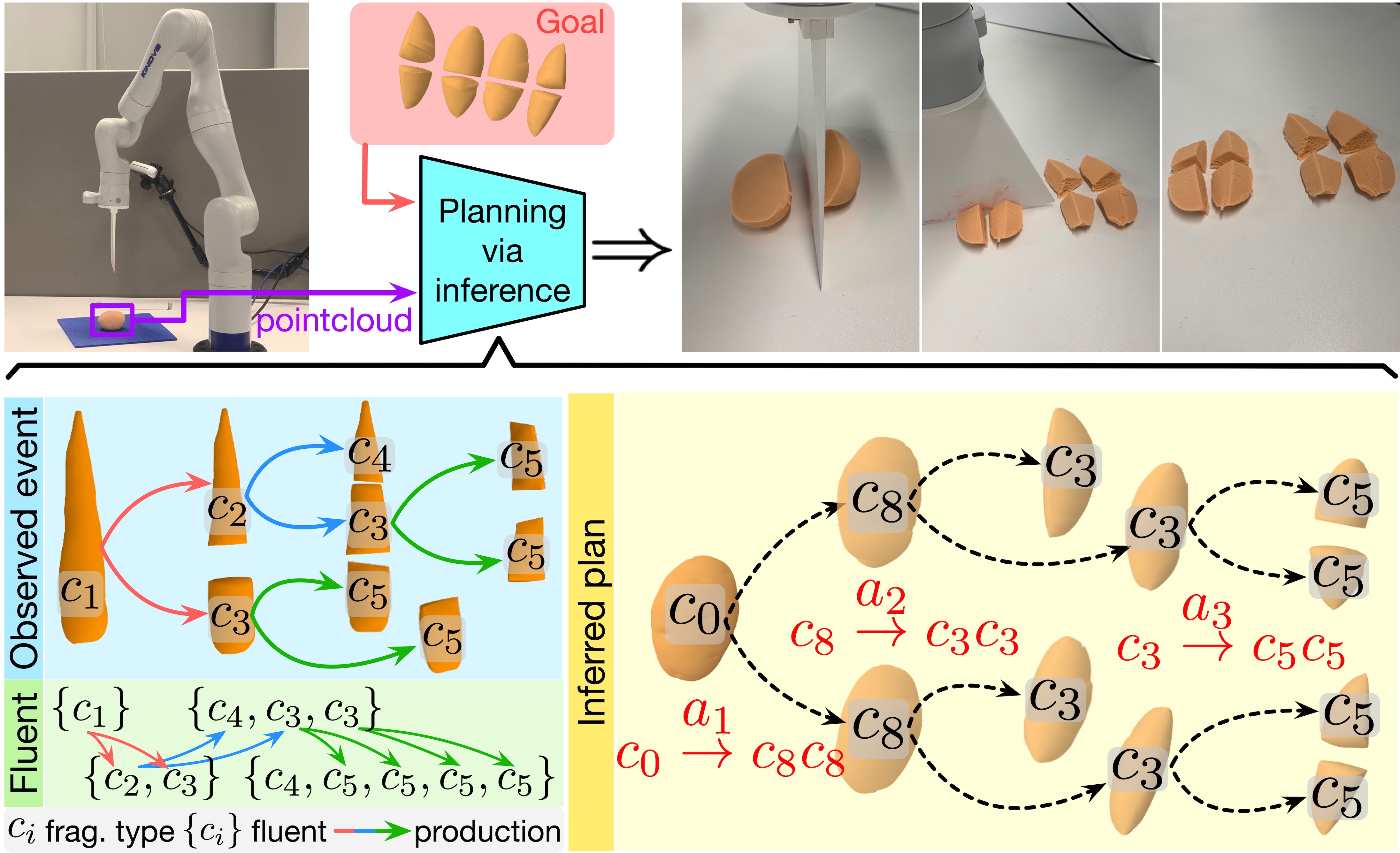
ManipulationTAMPSkill LearningIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023Cutting objects into desired fragments is challenging for robots due to the spatially unstructured nature of fragments and the complex one-to-many object fragmentation caused by actions. We present a novel approach to model object fragmentation using an attributed stochastic grammar. This grammar abstracts fragment states as node variables and captures causal transitions in object fragmentation through production rules. We devise a probabilistic framework to learn this grammar from human demonstrations. The planning process for object cutting involves inferring an optimal parse tree of desired fragments using the learned grammar, with parse tree productions corresponding to cutting actions. We employ Monte Carlo Tree Search (MCTS) to efficiently approximate the optimal parse tree and generate a sequence of executable cutting actions. The experiments demonstrate the efficacy in planning for object-cutting tasks, both in simulation and on a physical robot. The proposed approach outperforms several baselines by demonstrating superior generalization to novel setups, thanks to the compositionality of the grammar model.
@inproceedings{zhang2023learning, title = {Learning a Causal Transition Model for Object Cutting}, author = {Zhang, Zeyu and Han, Muzhi and Jia, Baoxiong and Jiao, Ziyuan and Zhu, Yixin and Zhu, Song-Chun and Liu, Hangxin}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {1996--2003}, year = {2023}, organization = {IEEE}, } - X-VoE: Measuring Explanatory Violation of Expectation in Physical Events
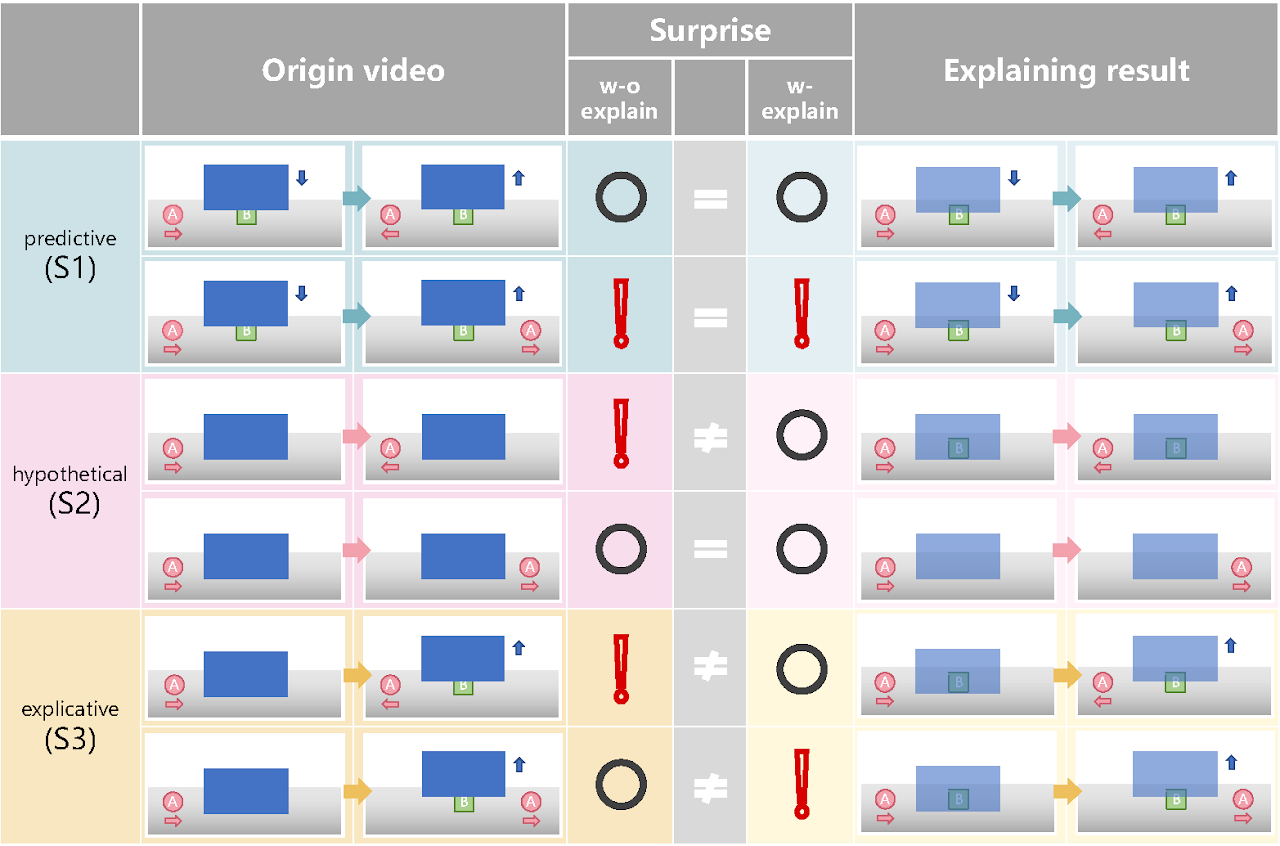
PhysicsCogSciIn In Proceedings of the International Conference on Computer Vision (ICCV), 2023Intuitive physics is pivotal for human understanding of the physical world, enabling prediction and interpretation of events even in infancy. Nonetheless, replicating this level of intuitive physics in artificial intelligence (AI) remains a formidable challenge. This study introduces X-VoE, a comprehensive benchmark dataset, to assess AI agents’ grasp of intuitive physics. Built on the developmental psychology-rooted Violation of Expectation (VoE) paradigm, X-VoE establishes a higher bar for the explanatory capacities of intuitive physics models. Each VoE scenario within X-VoE encompasses three distinct settings, probing models’ comprehension of events and their underlying explanations. Beyond model evaluation, we present an explanation-based learning system that captures physics dynamics and infers occluded object states solely from visual sequences, without explicit occlusion labels. Experimental outcomes highlight our model’s alignment with human commonsense when tested against X-VoE. A remarkable feature is our model’s ability to visually expound VoE events by reconstructing concealed scenes. Concluding, we discuss the findings’ implications and outline future research directions. Through X-VoE, we catalyze the advancement of AI endowed with human-like intuitive physics capabilities.
@inproceedings{dai2023x, title = {X-VoE: Measuring Explanatory Violation of Expectation in Physical Events}, author = {Dai, Bo and Wang, Linge and Jia, Baoxiong and Zhang, Zeyu and Zhu, Song-Chun and Zhang, Chi and Zhu, Yixin}, booktitle = {In Proceedings of the International Conference on Computer Vision (ICCV)}, pages = {3992--4002}, year = {2023}, }
2022
- Sequential Manipulation Planning on Scene Graph
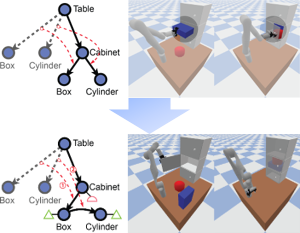
ManipulationTAMPIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022We devise a 3D scene graph representation, contact graph+ (cg+), for efficient sequential task planning. Augmented with predicate-like attributes, this contact graph-based representation abstracts scene layouts with succinct geometric information and valid robot-scene interactions. Goal configurations, naturally specified on contact graphs, can be produced by a genetic algorithm with a stochastic optimization method. A task plan is then initialized by computing the Graph Editing Distance (GED) between the initial contact graphs and the goal configurations, which generates graph edit operations corresponding to possible robot actions. We finalize the task plan by imposing constraints to regulate the temporal feasibility of graph edit operations, ensuring valid task and motion correspondences. In a series of simulations and experiments, robots successfully complete complex sequential object rearrangement tasks that are difficult to specify using conventional planning language like Planning Domain Definition Language (PDDL), demonstrating the high feasibility and potential of robot sequential task planning on contact graph.
@inproceedings{jiao2022sequential, title = {Sequential Manipulation Planning on Scene Graph}, author = {Jiao, Ziyuan and Niu, Yida and Zhang, Zeyu and Zhu, Song-Chun and Zhu, Yixin and Liu, Hangxin}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {8203--8210}, year = {2022}, organization = {IEEE}, } - Understanding Physical Effects for Effective Tool-use
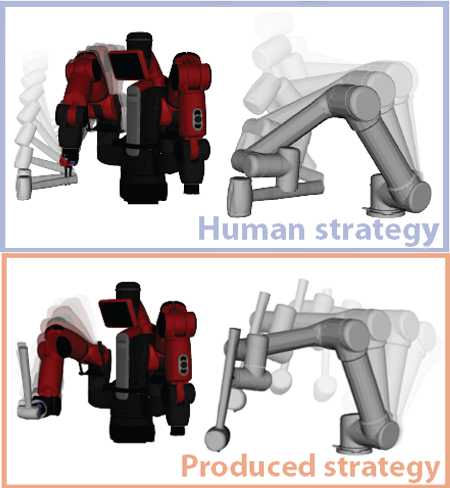
ToolManipulationFunctionalityAffordanceHOIIEEE Robotics and Automation Letters (RA-L), 2022We present a robot learning and planning framework that produces an effective tool-use strategy with the least joint efforts, capable of handling objects different from training. Leveraging a Finite Element Method (FEM)-based simulator that reproduces fine-grained, continuous visual and physical effects given observed tool-use events, the essential physical properties contributing to the effects are identified through the proposed Iterative Deepening Symbolic Regression (IDSR) algorithm. We further devise an optimal control-based motion planning scheme to integrate robot- and tool-specific kinematics and dynamics to produce an effective trajectory that enacts the learned properties. In simulation, we demonstrate that the proposed framework can produce more effective tool-use strategies, drastically different from the observed ones in two exemplar tasks.
@article{zhang2022understanding, title = {Understanding Physical Effects for Effective Tool-use}, author = {Zhang, Zeyu and Jiao, Ziyuan and Wang, Weiqi and Zhu, Yixin and Zhu, Song-Chun and Liu, Hangxin}, journal = {IEEE Robotics and Automation Letters (RA-L)}, volume = {7}, number = {4}, pages = {9469--9476}, year = {2022}, publisher = {IEEE}, } - Scene Reconstruction with Functional Objects for Robot Autonomy
Scene ReconstructionFunctionalityDigital TwinInternational Journal of Computer Vision (IJCV), 2022We present a robot learning and planning framework that produces an effective tool-use strategy with the least joint efforts, capable of handling objects different from training. Leveraging a Finite Element Method (FEM)-based simulator that reproduces fine-grained, continuous visual and physical effects given observed tool-use events, the essential physical properties contributing to the effects are identified through the proposed Iterative Deepening Symbolic Regression (IDSR) algorithm. We further devise an optimal control-based motion planning scheme to integrate robot- and tool-specific kinematics and dynamics to produce an effective trajectory that enacts the learned properties. In simulation, we demonstrate that the proposed framework can produce more effective tool-use strategies, drastically different from the observed ones in two exemplar tasks.
@article{han2022scene, title = {Scene Reconstruction with Functional Objects for Robot Autonomy}, author = {Han, Muzhi and Zhang, Zeyu and Jiao, Ziyuan and Xie, Xu and Zhu, Yixin and Zhu, Song-Chun and Liu, Hangxin}, journal = {International Journal of Computer Vision (IJCV)}, volume = {130}, number = {12}, pages = {2940--2961}, year = {2022}, publisher = {Springer}, }

2021
- Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments
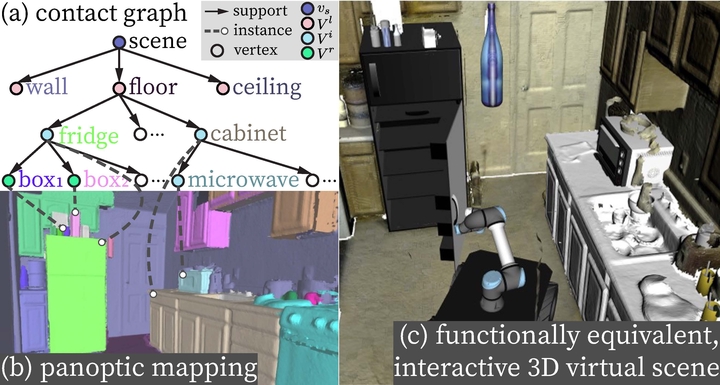
Scene ReconstructionFunctionalityDigital TwinIn IEEE International Conference on Robotics and Automation (ICRA), 2021In this paper, we rethink the problem of scene reconstruction from an embodied agent’s perspective: While the classic view focuses on the reconstruction accuracy, our new perspective emphasizes the underlying functions and constraints such that the reconstructed scenes provide actionable information for simulating interactions with agents. Here, we address this challenging problem by reconstructing an interactive scene using RGB-D data stream, which captures (i) the semantics and geometry of objects and layouts by a 3D volumetric panoptic mapping module, and (ii) object affordance and contextual relations by reasoning over physical common sense among objects, organized by a graph-based scene representation. Crucially, this reconstructed scene replaces the object meshes in the dense panoptic map with part-based articulated CAD models for finer-grained robot interactions. In the experiments, we demonstrate that (i) our panoptic mapping module outperforms previous state-of-the-art methods, (ii) a high-performant physical reasoning procedure that matches, aligns, and replaces objects’ meshes with best-fitted CAD models, and (iii) reconstructed scenes are physically plausible and naturally afford actionable interactions; without any manual labeling, they are seamlessly imported to ROS-based simulators and virtual environments for complex robot task executions.
@inproceedings{han2021reconstructing, title = {Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments}, author = {Han, Muzhi and Zhang, Zeyu and Jiao, Ziyuan and Xie, Xu and Zhu, Yixin and Zhu, Song-Chun and Liu, Hangxin}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, pages = {12199--12206}, year = {2021}, organization = {IEEE}, } - Consolidating Kinematic Models to Promote Coordinated Mobile Manipulations
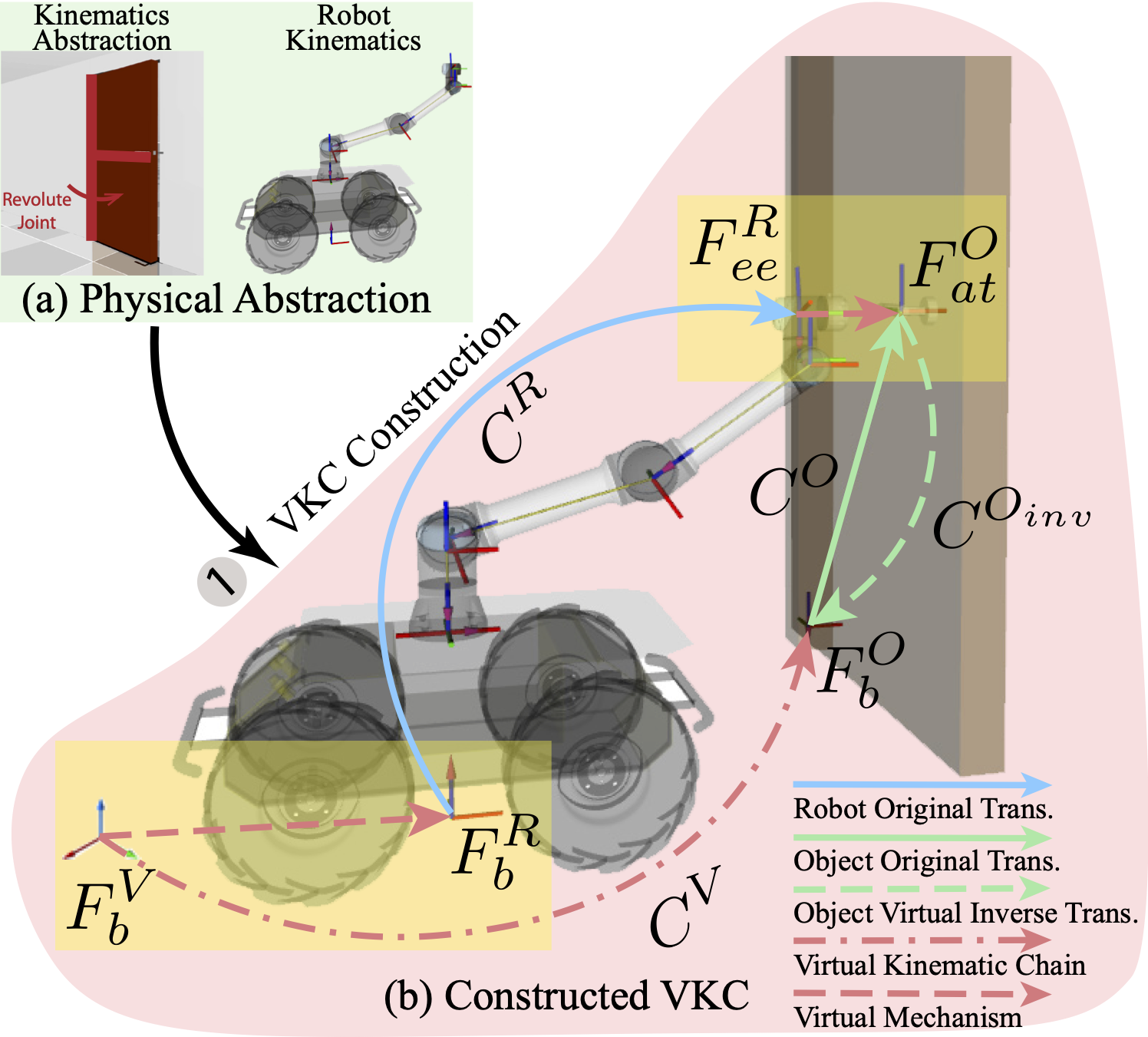
ManipulationTAMPIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021We construct a Virtual Kinematic Chain (VKC) that readily consolidates the kinematics of the mobile base, the arm, and the object to be manipulated in mobile manipulations. Accordingly, a mobile manipulation task is represented by altering the state of the constructed VKC, which can be converted to a motion planning problem, formulated, and solved by trajectory optimization. This new VKC perspective of mobile manipulation allows a service robot to (i) produce well-coordinated motions, suitable for complex household environments, and (ii) perform intricate multi-step tasks while interacting with multiple objects without an explicit definition of intermediate goals. In simulated experiments, we validate these advantages by comparing the VKC-based approach with baselines that solely optimize individual components. The results manifest that VKC-based joint modeling and planning promote task success rates and produce more efficient trajectories.
@inproceedings{jiao2021consolidating, title = {Consolidating Kinematic Models to Promote Coordinated Mobile Manipulations}, author = {Jiao, Ziyuan and Zhang, Zeyu and Jiang, Xin and Han, David and Zhu, Song-Chun and Zhu, Yixin and Liu, Hangxin}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {979--985}, year = {2021}, organization = {IEEE}, } - Efficient Task Planning for Mobile Manipulation: a Virtual Kinematic Chain Perspective
ManipulationTAMPIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021We present a Virtual Kinematic Chain (VKC) perspective, a simple yet effective method, to improve task planning efficacy for mobile manipulation. By consolidating the kinematics of the mobile base, the arm, and the object to be manipulated collectively as a whole, our novel VKC perspective naturally defines abstract actions and eliminates unnecessary predicates in describing intermediate poses. As a result, these advantages simplify the design of the planning domain and significantly reduce the search space and branching factors in solving planning problems. In experiments, we implement a task planner using Planning Domain Definition Language (PDDL) with VKC. Compared with classic domain definition, our VKC-based domain definition is more efficient in both planning time and memory required. In addition, the abstract actions perform better in producing feasible motion plans and trajectories. We further scale up the VKC-based task planner in complex mobile manipulation tasks. Taken together, these results demonstrate that task planning using VKC for mobile manipulation is not only natural and effective but also introduces new capabilities.
@inproceedings{jiao2021efficient, title = {Efficient Task Planning for Mobile Manipulation: a Virtual Kinematic Chain Perspective}, author = {Jiao, Ziyuan and Zhang, Zeyu and Wang, Weiqi and Han, David and Zhu, Song-Chun and Zhu, Yixin and Liu, Hangxin}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {8288--8294}, year = {2021}, organization = {IEEE}, }

2020
- Congestion-aware Evacuation Routing using Augmented Reality Devices
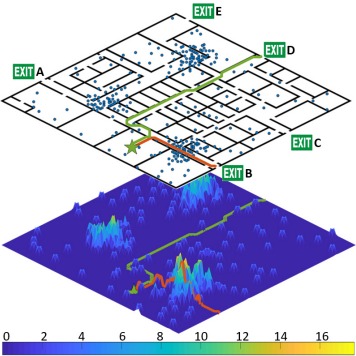
TeamingARIn IEEE International Conference on Robotics and Automation (ICRA), 2020We present a congestion-aware routing solution for indoor evacuation, which produces real-time individual-customized evacuation routes among multiple destinations while keeping tracks of all evacuees’ locations. A population density map, obtained on-the-fly by aggregating locations of evacuees from user-end AR devices, is used to model the congestion distribution inside a building. To efficiently search the evacuation route among all destinations, a variant of A* algorithm is devised to obtain the optimal solution in a single pass. In a series of simulated studies, we show that the proposed algorithm is more computationally optimized compared to classic path planning algorithms; it generates a more time-efficient evacuation route for each individual that minimizes the overall congestion. A complete system using AR devices is implemented for a pilot study in real-world environments, demonstrating the efficacy of the proposed approach.
@inproceedings{zhang2020congestion, title = {Congestion-aware Evacuation Routing using Augmented Reality Devices}, author = {Zhang, Zeyu and Liu, Hangxin and Jiao, Ziyuan and Zhu, Yixin and Zhu, Song-Chun}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, pages = {2798--2804}, year = {2020}, organization = {IEEE}, } - Human-robot Interaction in a Shared Augmented Reality Workspace
TeamingARIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020We design and develop a new shared Augmented Reality (AR) workspace for Human-Robot Interaction (HRI), which establishes a bi-directional communication between human agents and robots. In a prototype system, the shared AR workspace enables a shared perception, so that a physical robot not only perceives the virtual elements in its own view but also infers the utility of the human agent—the cost needed to perceive and interact in AR—by sensing the human agent’s gaze and pose. Such a new HRI design also affords a shared manipulation, wherein the physical robot can control and alter virtual objects in AR as an active agent; crucially, a robot can proactively interact with human agents, instead of purely passively executing received commands. In experiments, we design a resource collection game that qualitatively demonstrates how a robot perceives, processes, and manipulates in AR and quantitatively evaluates the efficacy of HRI using the shared AR workspace. We further discuss how the system can potentially benefit future HRI studies that are otherwise challenging.
@inproceedings{qiu2020human, title = {Human-robot Interaction in a Shared Augmented Reality Workspace}, author = {Qiu, Shuwen and Liu, Hangxin and Zhang, Zeyu and Zhu, Yixin and Zhu, Song-Chun}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {11413--11418}, year = {2020}, organization = {IEEE}, }

2019
- Self-supervised Incremental Learning for Sound Source Localization in Complex Indoor Environment
TeamingIn IEEE International Conference on Robotics and Automation (ICRA), 2019This paper presents an incremental learning framework for mobile robots localizing the human sound source using a microphone array in a complex indoor environment consisting of multiple rooms. In contrast to conventional approaches that leverage direction-of-arrival estimation, the framework allows a robot to accumulate training data and improve the performance of the prediction model over time using an incremental learning scheme. Specifically, we use implicit acoustic features obtained from an auto-encoder together with the geometry features from the map for training. A self-supervision process is developed such that the model ranks the priority of rooms to explore and assigns the ground truth label to the collected data, updating the learned model on-the-fly. The framework does not require pre-collected data and can be directly applied to real-world scenarios without any human supervisions or interventions. In experiments, we demonstrate that the prediction accuracy reaches 67% using about 20 training samples and eventually achieves 90% accuracy within 120 samples, surpassing prior classification-based methods with explicit GCC-PHAT features.
@inproceedings{liu2019self, title = {Self-supervised Incremental Learning for Sound Source Localization in Complex Indoor Environment}, author = {Liu, Hangxin and Zhang, Zeyu and Zhu, Yixin and Zhu, Song-Chun}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, pages = {2599--2605}, year = {2019}, organization = {IEEE}, }